{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "uUvsR-mWBoNS"
},
"source": [
"# Perform Multi-Table Synthesization  \n",
"\n",
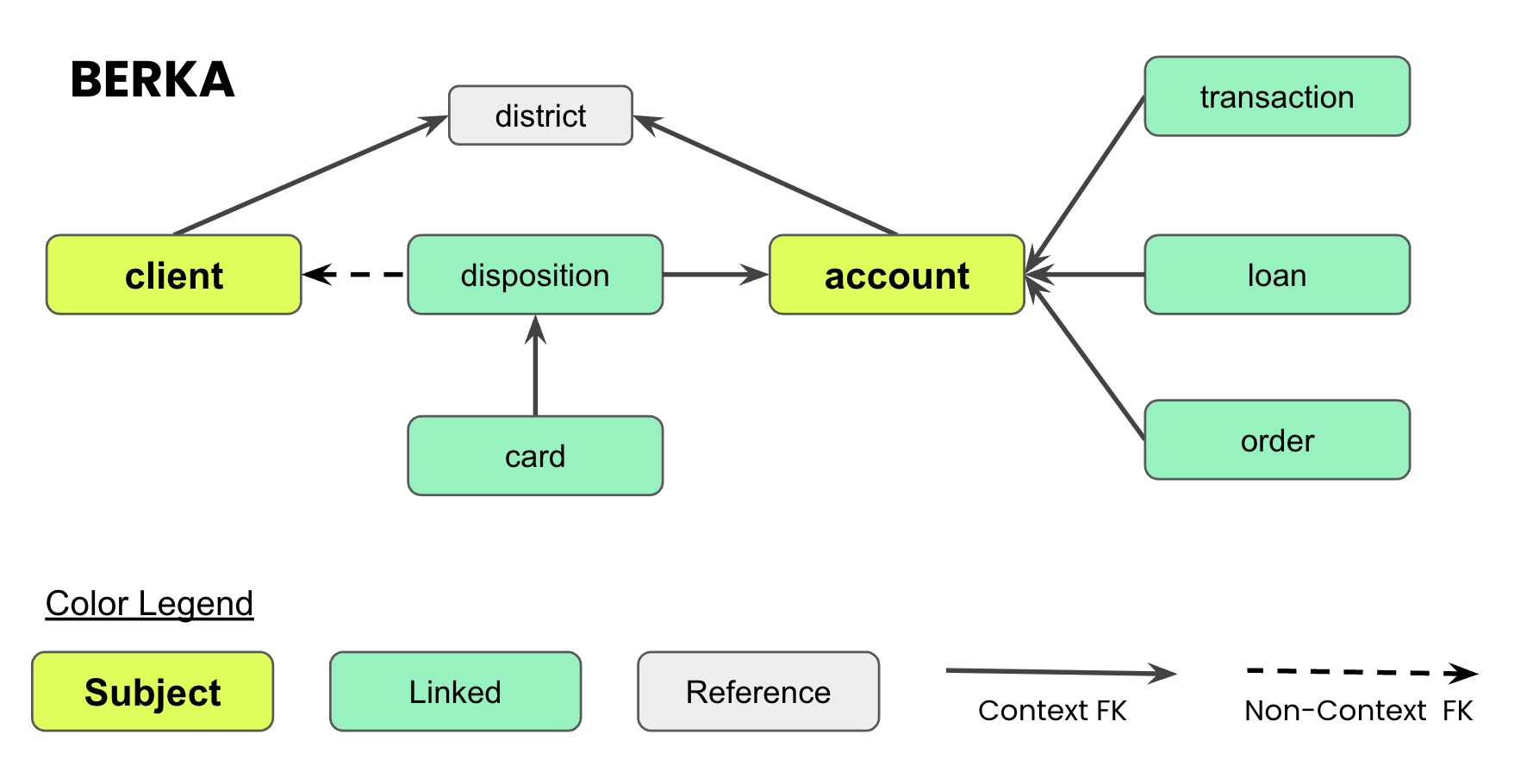
"In this exercise, we are going to walk through the synthesis of a relational multi-table structure. For that, we will be using the Berka dataset [[1](#refs)]: a dataset containing Czech bank transactions. It consists of a total of 8 tables, whereas one of these (\"district\") only serves as a basic reference table, while all others are considered to be privacy-sensitive and thus are being synthesized.\n",
"\n",
"
\n",
"\n",
"In this exercise, we are going to walk through the synthesis of a relational multi-table structure. For that, we will be using the Berka dataset [[1](#refs)]: a dataset containing Czech bank transactions. It consists of a total of 8 tables, whereas one of these (\"district\") only serves as a basic reference table, while all others are considered to be privacy-sensitive and thus are being synthesized.\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Data preparation\n",
"\n",
"Fetch original data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": "%pip install -U mostlyai # or: pip install -U 'mostlyai[local]'"
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"\n",
"base_url = \"https://github.com/mostly-ai/public-demo-data/raw/dev/berka/data/\"\n",
"originals = {\n",
" \"client\": pd.read_csv(base_url + \"client.csv.gz\", low_memory=False),\n",
" \"disposition\": pd.read_csv(base_url + \"disp.csv.gz\", low_memory=False),\n",
" \"card\": pd.read_csv(base_url + \"card.csv.gz\", low_memory=False),\n",
" \"account\": pd.read_csv(base_url + \"account.csv.gz\", low_memory=False),\n",
" \"transaction\": pd.read_csv(base_url + \"trans.csv.gz\", low_memory=False),\n",
" \"loan\": pd.read_csv(base_url + \"loan.csv.gz\", low_memory=False),\n",
" \"order\": pd.read_csv(base_url + \"order.csv.gz\", low_memory=False),\n",
"}\n",
"originals[\"account\"][\"date\"] = pd.to_datetime(originals[\"account\"][\"date\"])\n",
"originals[\"transaction\"][\"date\"] = pd.to_datetime(originals[\"transaction\"][\"date\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for k in originals:\n",
" print(\"===\", k, \"===\")\n",
" display(originals[k].sample(n=3))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oZ7ERZK__8TB",
"tags": []
},
"source": [
"## Train a multi-table generator\n",
"\n",
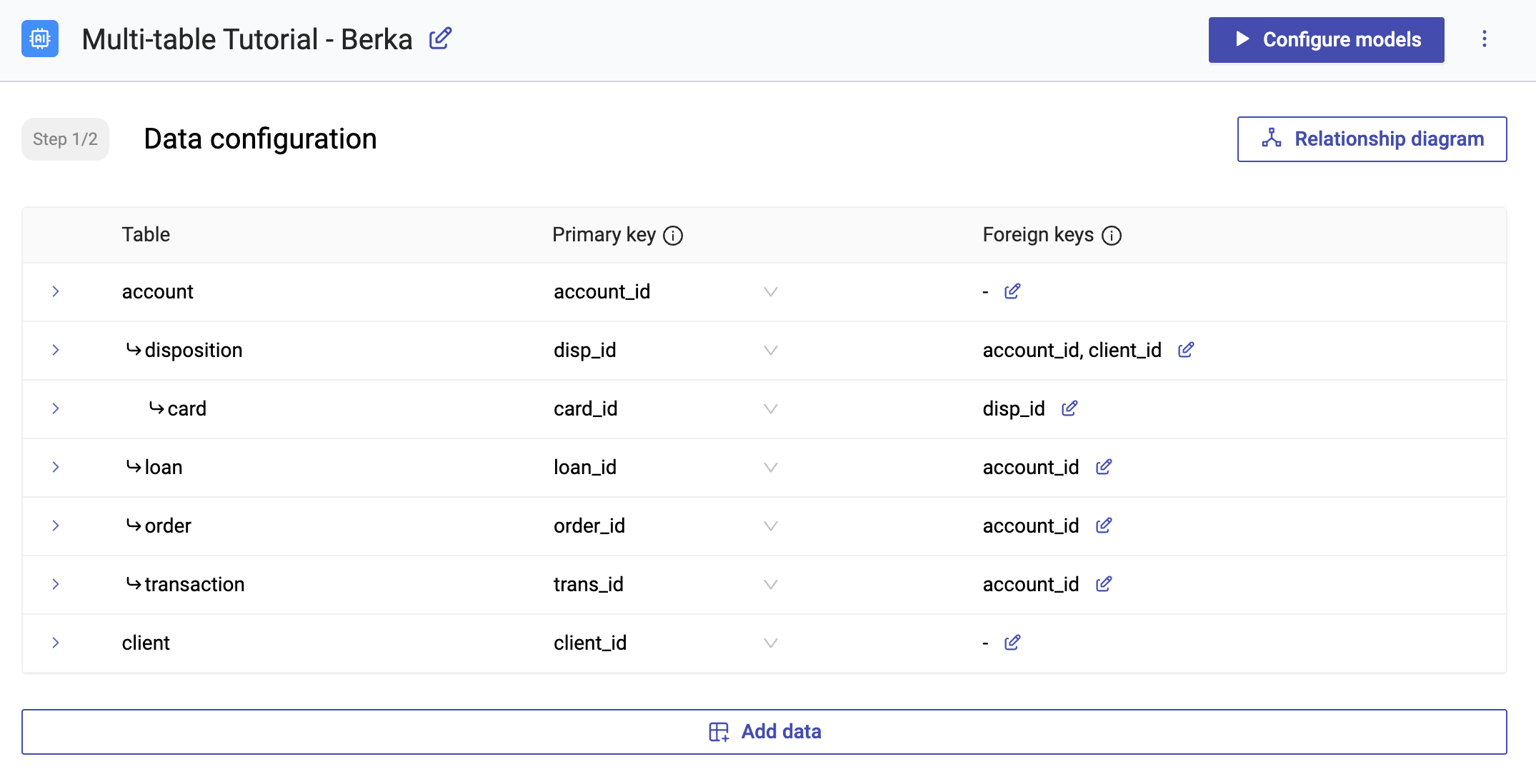
"Configuring a mutli-table generator is simply done, by configuring each table, their primary key as well as all their foreign key relations.\n",
"\n",
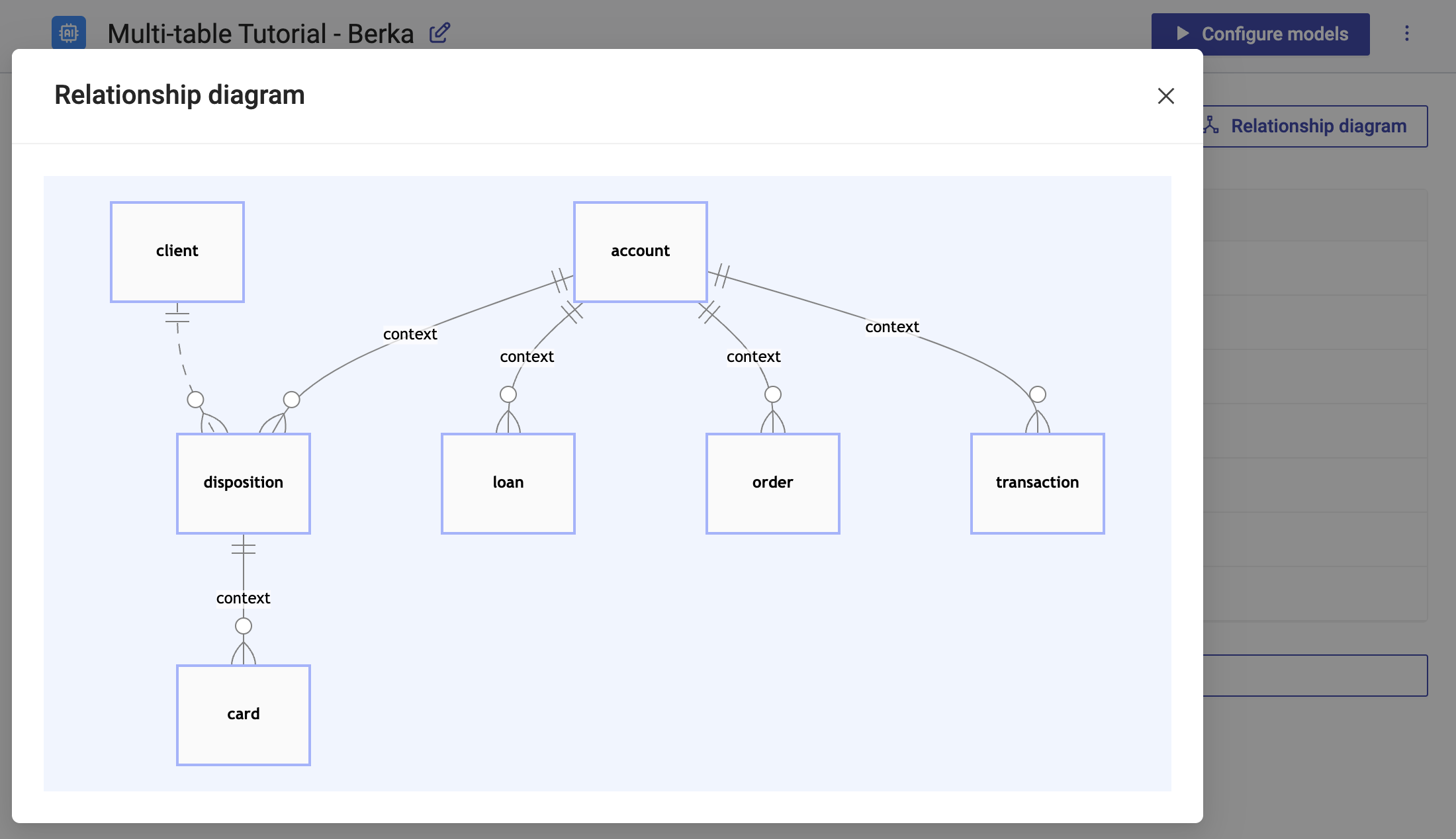
"As can be seen from the entity relationship diagram above, the Berka dataset has two privacy-sensitive tables, that do not reference any other privacy-sensitive table. These two top-level tables (\"client\" and \"account\") will act as our subject tables, that are independently generated. All other tables are linked to these, and thus will also then be generated in their context.\n",
"\n",
"Additionally, it can be seen, that the two subject tables share the same child table named \"disposition\". MOSTLY AI supports retaining the correlations between a child and its parent table (as well as to its great-parent and parent-sibling), but this can only be configured for a single parent (the so called \"context\" parent). We therefore have to decide which of these two foreign key relationships is then considered as context, and which not. Only for the former correlations can be retained across tables, while for the latter the parents will get randomly assigned (while still retaining referential integrity).\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Data preparation\n",
"\n",
"Fetch original data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": "%pip install -U mostlyai # or: pip install -U 'mostlyai[local]'"
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"\n",
"base_url = \"https://github.com/mostly-ai/public-demo-data/raw/dev/berka/data/\"\n",
"originals = {\n",
" \"client\": pd.read_csv(base_url + \"client.csv.gz\", low_memory=False),\n",
" \"disposition\": pd.read_csv(base_url + \"disp.csv.gz\", low_memory=False),\n",
" \"card\": pd.read_csv(base_url + \"card.csv.gz\", low_memory=False),\n",
" \"account\": pd.read_csv(base_url + \"account.csv.gz\", low_memory=False),\n",
" \"transaction\": pd.read_csv(base_url + \"trans.csv.gz\", low_memory=False),\n",
" \"loan\": pd.read_csv(base_url + \"loan.csv.gz\", low_memory=False),\n",
" \"order\": pd.read_csv(base_url + \"order.csv.gz\", low_memory=False),\n",
"}\n",
"originals[\"account\"][\"date\"] = pd.to_datetime(originals[\"account\"][\"date\"])\n",
"originals[\"transaction\"][\"date\"] = pd.to_datetime(originals[\"transaction\"][\"date\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for k in originals:\n",
" print(\"===\", k, \"===\")\n",
" display(originals[k].sample(n=3))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oZ7ERZK__8TB",
"tags": []
},
"source": [
"## Train a multi-table generator\n",
"\n",
"Configuring a mutli-table generator is simply done, by configuring each table, their primary key as well as all their foreign key relations.\n",
"\n",
"As can be seen from the entity relationship diagram above, the Berka dataset has two privacy-sensitive tables, that do not reference any other privacy-sensitive table. These two top-level tables (\"client\" and \"account\") will act as our subject tables, that are independently generated. All other tables are linked to these, and thus will also then be generated in their context.\n",
"\n",
"Additionally, it can be seen, that the two subject tables share the same child table named \"disposition\". MOSTLY AI supports retaining the correlations between a child and its parent table (as well as to its great-parent and parent-sibling), but this can only be configured for a single parent (the so called \"context\" parent). We therefore have to decide which of these two foreign key relationships is then considered as context, and which not. Only for the former correlations can be retained across tables, while for the latter the parents will get randomly assigned (while still retaining referential integrity).\n",
"\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from mostlyai.sdk import MostlyAI\n",
"\n",
"# initialize SDK\n",
"mostly = MostlyAI()\n",
"\n",
"config = {\n",
" \"name\": \"Multi-table Tutorial - Berka\",\n",
" \"tables\": [\n",
" {\"name\": \"client\", \"data\": originals[\"client\"], \"primary_key\": \"client_id\"},\n",
" {\n",
" \"name\": \"disposition\",\n",
" \"data\": originals[\"disposition\"],\n",
" \"primary_key\": \"disp_id\",\n",
" \"foreign_keys\": [\n",
" {\"column\": \"account_id\", \"referenced_table\": \"account\", \"is_context\": True},\n",
" {\"column\": \"client_id\", \"referenced_table\": \"client\", \"is_context\": False},\n",
" ],\n",
" },\n",
" {\n",
" \"name\": \"card\",\n",
" \"data\": originals[\"card\"],\n",
" \"primary_key\": \"card_id\",\n",
" \"foreign_keys\": [{\"column\": \"disp_id\", \"referenced_table\": \"disposition\", \"is_context\": True}],\n",
" },\n",
" {\"name\": \"account\", \"data\": originals[\"account\"], \"primary_key\": \"account_id\"},\n",
" {\n",
" \"name\": \"transaction\",\n",
" \"data\": originals[\"transaction\"],\n",
" \"primary_key\": \"trans_id\",\n",
" \"foreign_keys\": [{\"column\": \"account_id\", \"referenced_table\": \"account\", \"is_context\": True}],\n",
" },\n",
" {\n",
" \"name\": \"loan\",\n",
" \"data\": originals[\"loan\"],\n",
" \"primary_key\": \"loan_id\",\n",
" \"foreign_keys\": [{\"column\": \"account_id\", \"referenced_table\": \"account\", \"is_context\": True}],\n",
" },\n",
" {\n",
" \"name\": \"order\",\n",
" \"data\": originals[\"order\"],\n",
" \"primary_key\": \"order_id\",\n",
" \"foreign_keys\": [{\"column\": \"account_id\", \"referenced_table\": \"account\", \"is_context\": True}],\n",
" },\n",
" ],\n",
"}\n",
"\n",
"# configure a generator, but don't yet start the training thereof\n",
"g = mostly.train(config=config, start=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If you have instantiated the SDK in client mode, then you can now also inspect the configuration on the Web UI."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# open generator in a new browser tab\n",
"g.open()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"It will look like this:\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from mostlyai.sdk import MostlyAI\n",
"\n",
"# initialize SDK\n",
"mostly = MostlyAI()\n",
"\n",
"config = {\n",
" \"name\": \"Multi-table Tutorial - Berka\",\n",
" \"tables\": [\n",
" {\"name\": \"client\", \"data\": originals[\"client\"], \"primary_key\": \"client_id\"},\n",
" {\n",
" \"name\": \"disposition\",\n",
" \"data\": originals[\"disposition\"],\n",
" \"primary_key\": \"disp_id\",\n",
" \"foreign_keys\": [\n",
" {\"column\": \"account_id\", \"referenced_table\": \"account\", \"is_context\": True},\n",
" {\"column\": \"client_id\", \"referenced_table\": \"client\", \"is_context\": False},\n",
" ],\n",
" },\n",
" {\n",
" \"name\": \"card\",\n",
" \"data\": originals[\"card\"],\n",
" \"primary_key\": \"card_id\",\n",
" \"foreign_keys\": [{\"column\": \"disp_id\", \"referenced_table\": \"disposition\", \"is_context\": True}],\n",
" },\n",
" {\"name\": \"account\", \"data\": originals[\"account\"], \"primary_key\": \"account_id\"},\n",
" {\n",
" \"name\": \"transaction\",\n",
" \"data\": originals[\"transaction\"],\n",
" \"primary_key\": \"trans_id\",\n",
" \"foreign_keys\": [{\"column\": \"account_id\", \"referenced_table\": \"account\", \"is_context\": True}],\n",
" },\n",
" {\n",
" \"name\": \"loan\",\n",
" \"data\": originals[\"loan\"],\n",
" \"primary_key\": \"loan_id\",\n",
" \"foreign_keys\": [{\"column\": \"account_id\", \"referenced_table\": \"account\", \"is_context\": True}],\n",
" },\n",
" {\n",
" \"name\": \"order\",\n",
" \"data\": originals[\"order\"],\n",
" \"primary_key\": \"order_id\",\n",
" \"foreign_keys\": [{\"column\": \"account_id\", \"referenced_table\": \"account\", \"is_context\": True}],\n",
" },\n",
" ],\n",
"}\n",
"\n",
"# configure a generator, but don't yet start the training thereof\n",
"g = mostly.train(config=config, start=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If you have instantiated the SDK in client mode, then you can now also inspect the configuration on the Web UI."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# open generator in a new browser tab\n",
"g.open()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"It will look like this:\n",
"\n",
" \n",
"
\n",
" \n",
"\n",
"Now, launch the training, and wait for it to be finished. This shouldn't take longer than 10 minutes."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true,
"tags": []
},
"outputs": [],
"source": [
"g.training.start()\n",
"g = g.training.wait(progress_bar=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Generate a multi-table dataset\n",
"\n",
"Once, the training has completed, you can generate a multi-table dataset with. If you do not specify the sample size, then the platform will generate as many subject records, as there were in the original subject tables. Otherwise, you will need to specify for each subject table, the number of records, as these are independently sampled."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"# generate a synthetic dataset\n",
"sd = mostly.generate(g, size={\"account\": 4500, \"client\": 5369}, start=False)\n",
"sd.open()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"sd.generation.start()\n",
"sd = sd.generation.wait(progress_bar=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# once done, fetch the synthetic data as dictionary of DataFrames\n",
"synthetics = sd.data()"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Show sample records for each table"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"for k in synthetics:\n",
" print(\"===\", k, \"===\")\n",
" display(synthetics[k].sample(n=3))"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Check basic statistics\n",
"\n",
"The newly generated tables are statistically representative of the original."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"display(synthetics[\"transaction\"][\"amount\"].quantile(q=[0.1, 0.5, 0.9]))\n",
"display(originals[\"transaction\"][\"amount\"].quantile(q=[0.1, 0.5, 0.9]))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"display(synthetics[\"transaction\"][\"date\"].quantile(q=[0.1, 0.5, 0.9], interpolation=\"nearest\"))\n",
"display(pd.to_datetime(originals[\"transaction\"][\"date\"]).quantile(q=[0.1, 0.5, 0.9], interpolation=\"nearest\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import matplotlib.pyplot as plt\n",
"\n",
"# Convert the 'date' column to datetime format for the third dataframe\n",
"originals[\"transaction\"][\"date\"] = pd.to_datetime(originals[\"transaction\"][\"date\"])\n",
"synthetics[\"transaction\"][\"date\"] = pd.to_datetime(synthetics[\"transaction\"][\"date\"])\n",
"\n",
"# Create the side-by-side scatter plots\n",
"fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(18, 6), sharey=True)\n",
"\n",
"# Plot original data\n",
"axes[0].scatter(originals[\"transaction\"][\"date\"], originals[\"transaction\"][\"amount\"], s=1, alpha=0.5)\n",
"axes[0].set_title(\"Amount vs Date (Original)\")\n",
"axes[0].set_xlabel(\"Date\")\n",
"axes[0].set_ylabel(\"Amount\")\n",
"axes[0].grid(True)\n",
"\n",
"# Plot synthetic data\n",
"axes[1].scatter(synthetics[\"transaction\"][\"date\"], synthetics[\"transaction\"][\"amount\"], s=1, alpha=0.5)\n",
"axes[1].set_title(\"Amount vs Date (MOSTLY AI)\")\n",
"axes[1].set_xlabel(\"Date\")\n",
"axes[1].grid(True)\n",
"\n",
"# Adjust layout\n",
"plt.tight_layout()\n",
"\n",
"# show\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Check referential integrity\n",
"\n",
"The newly generated foreign keys are also present as primary keys in the connected tables."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"assert synthetics[\"transaction\"][\"account_id\"].isin(synthetics[\"account\"][\"account_id\"]).all()\n",
"assert synthetics[\"card\"][\"disp_id\"].isin(synthetics[\"disposition\"][\"disp_id\"]).all()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Check context FK relations\n",
"\n",
"The cardinality of context FK relations is perfectly retained."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"print(\"Orders per Account - Synthetic\")\n",
"display(synthetics[\"order\"].groupby(\"account_id\").size().value_counts())\n",
"print(\"\\nOrders per Account - Original\")\n",
"display(originals[\"order\"].groupby(\"account_id\").size().value_counts())"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"print(\"Cards per Disposition - Synthetic\")\n",
"display(synthetics[\"card\"].groupby(\"disp_id\").size().value_counts())\n",
"print(\"\\nCards per Disposition - Original\")\n",
"display(originals[\"card\"].groupby(\"disp_id\").size().value_counts())"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## References\n",
"\n",
"1. https://data.world/lpetrocelli/czech-financial-dataset-real-anonymized-transactions"
]
}
],
"metadata": {
"colab": {
"provenance": []
},
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.11.8"
},
"vscode": {
"interpreter": {
"hash": "767d51c1340bd893661ea55ea3124f6de3c7a262a8b4abca0554b478b1e2ff90"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}
\n",
"\n",
"Now, launch the training, and wait for it to be finished. This shouldn't take longer than 10 minutes."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true,
"tags": []
},
"outputs": [],
"source": [
"g.training.start()\n",
"g = g.training.wait(progress_bar=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Generate a multi-table dataset\n",
"\n",
"Once, the training has completed, you can generate a multi-table dataset with. If you do not specify the sample size, then the platform will generate as many subject records, as there were in the original subject tables. Otherwise, you will need to specify for each subject table, the number of records, as these are independently sampled."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"# generate a synthetic dataset\n",
"sd = mostly.generate(g, size={\"account\": 4500, \"client\": 5369}, start=False)\n",
"sd.open()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"sd.generation.start()\n",
"sd = sd.generation.wait(progress_bar=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# once done, fetch the synthetic data as dictionary of DataFrames\n",
"synthetics = sd.data()"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Show sample records for each table"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"for k in synthetics:\n",
" print(\"===\", k, \"===\")\n",
" display(synthetics[k].sample(n=3))"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Check basic statistics\n",
"\n",
"The newly generated tables are statistically representative of the original."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"display(synthetics[\"transaction\"][\"amount\"].quantile(q=[0.1, 0.5, 0.9]))\n",
"display(originals[\"transaction\"][\"amount\"].quantile(q=[0.1, 0.5, 0.9]))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"display(synthetics[\"transaction\"][\"date\"].quantile(q=[0.1, 0.5, 0.9], interpolation=\"nearest\"))\n",
"display(pd.to_datetime(originals[\"transaction\"][\"date\"]).quantile(q=[0.1, 0.5, 0.9], interpolation=\"nearest\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import matplotlib.pyplot as plt\n",
"\n",
"# Convert the 'date' column to datetime format for the third dataframe\n",
"originals[\"transaction\"][\"date\"] = pd.to_datetime(originals[\"transaction\"][\"date\"])\n",
"synthetics[\"transaction\"][\"date\"] = pd.to_datetime(synthetics[\"transaction\"][\"date\"])\n",
"\n",
"# Create the side-by-side scatter plots\n",
"fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(18, 6), sharey=True)\n",
"\n",
"# Plot original data\n",
"axes[0].scatter(originals[\"transaction\"][\"date\"], originals[\"transaction\"][\"amount\"], s=1, alpha=0.5)\n",
"axes[0].set_title(\"Amount vs Date (Original)\")\n",
"axes[0].set_xlabel(\"Date\")\n",
"axes[0].set_ylabel(\"Amount\")\n",
"axes[0].grid(True)\n",
"\n",
"# Plot synthetic data\n",
"axes[1].scatter(synthetics[\"transaction\"][\"date\"], synthetics[\"transaction\"][\"amount\"], s=1, alpha=0.5)\n",
"axes[1].set_title(\"Amount vs Date (MOSTLY AI)\")\n",
"axes[1].set_xlabel(\"Date\")\n",
"axes[1].grid(True)\n",
"\n",
"# Adjust layout\n",
"plt.tight_layout()\n",
"\n",
"# show\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Check referential integrity\n",
"\n",
"The newly generated foreign keys are also present as primary keys in the connected tables."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"assert synthetics[\"transaction\"][\"account_id\"].isin(synthetics[\"account\"][\"account_id\"]).all()\n",
"assert synthetics[\"card\"][\"disp_id\"].isin(synthetics[\"disposition\"][\"disp_id\"]).all()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Check context FK relations\n",
"\n",
"The cardinality of context FK relations is perfectly retained."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"print(\"Orders per Account - Synthetic\")\n",
"display(synthetics[\"order\"].groupby(\"account_id\").size().value_counts())\n",
"print(\"\\nOrders per Account - Original\")\n",
"display(originals[\"order\"].groupby(\"account_id\").size().value_counts())"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"print(\"Cards per Disposition - Synthetic\")\n",
"display(synthetics[\"card\"].groupby(\"disp_id\").size().value_counts())\n",
"print(\"\\nCards per Disposition - Original\")\n",
"display(originals[\"card\"].groupby(\"disp_id\").size().value_counts())"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## References\n",
"\n",
"1. https://data.world/lpetrocelli/czech-financial-dataset-real-anonymized-transactions"
]
}
],
"metadata": {
"colab": {
"provenance": []
},
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.11.8"
},
"vscode": {
"interpreter": {
"hash": "767d51c1340bd893661ea55ea3124f6de3c7a262a8b4abca0554b478b1e2ff90"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}