{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "uUvsR-mWBoNS"
},
"source": [
"# Develop a Fake or Real Discriminator  \n",
"\n",
"In this notebook, we walk through the steps of developing a machine learning model that is trained to distinguish between fake (=synthetic) and real records. The model's ability to correctly discriminate between these on an unseen holdout can serve us as another helpful quality criteria for the generated synthetic data. The more realistic those synthetic records are, the harder it will be for any discriminator to tell these apart from the real records.\n",
"\n",
"
\n",
"\n",
"In this notebook, we walk through the steps of developing a machine learning model that is trained to distinguish between fake (=synthetic) and real records. The model's ability to correctly discriminate between these on an unseen holdout can serve us as another helpful quality criteria for the generated synthetic data. The more realistic those synthetic records are, the harder it will be for any discriminator to tell these apart from the real records.\n",
"\n",
"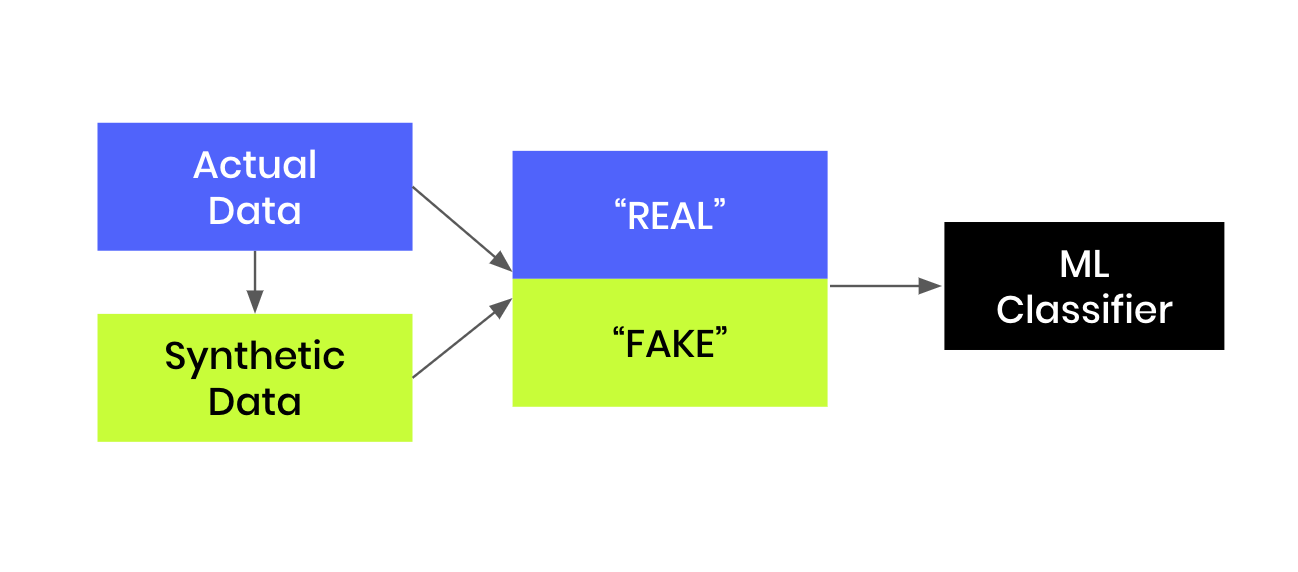 \n",
"\n",
"In order to make the analysis more interesting, we intentionally create synthetic data of lower quality, by limiting the training samples to only a thousand records. Otherwise, the discriminator would not be able to find much signal, if the synthesizer, like MOSTLY AI Synthetic Data SDK, is of very high quality."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MKRa93uuSqZS"
},
"source": [
"## Synthesize Data via MOSTLY AI\n",
"\n",
"For this tutorial, we will be using again the UCI Adult Income [[1](#refs)] dataset, which consists of 48,842 records across 15 attributes.\n",
"\n",
"We will use the Synthetic Data SDK to create a Generator and then use that Generator to create a Synthetic dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%pip install -U mostlyai # or: pip install -U 'mostlyai[local]'\n",
"%pip install scikit-learn seaborn lightgbm"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"\n",
"# fetch original data\n",
"df_tgt = pd.read_csv(\"https://github.com/mostly-ai/public-demo-data/raw/dev/census/census.csv.gz\")\n",
"df_tgt"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from mostlyai.sdk import MostlyAI\n",
"\n",
"# initialize SDK\n",
"mostly = MostlyAI()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# create generator with a sample of 5,000\n",
"g = mostly.train(\n",
" config={\n",
" \"name\": \"Fake vs. Real Tutorial - Census Data\",\n",
" \"tables\": [\n",
" {\n",
" \"name\": \"data\",\n",
" \"data\": df_tgt,\n",
" \"tabular_model_configuration\": {\n",
" \"max_sample_size\": 5_000,\n",
" \"max_training_time\": 2,\n",
" },\n",
" }\n",
" ],\n",
" }\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Generate synthetic data\n",
"syn = mostly.probe(g, size=5_000)\n",
"print(f\"Created synthetic data with {syn.shape[0]:,} records and {syn.shape[1]:,} attributes\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "OgvJ0XoWTHoX"
},
"source": [
"## Train Discriminator"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Rl6-YXB_e0Ac",
"tags": []
},
"outputs": [],
"source": [
"import lightgbm as lgb\n",
"from lightgbm import early_stopping\n",
"from sklearn.model_selection import train_test_split\n",
"\n",
"\n",
"def prepare_xy(df, target_col, target_val):\n",
" # split target variable `y`\n",
" y = (df[target_col] == target_val).astype(int)\n",
" # convert strings to categoricals, and all others to floats\n",
" str_cols = [col for col in df.select_dtypes([\"object\", \"string\"]).columns if col != target_col]\n",
" for col in str_cols:\n",
" df[col] = pd.Categorical(df[col])\n",
" cat_cols = [col for col in df.select_dtypes(\"category\").columns if col != target_col]\n",
" num_cols = [col for col in df.select_dtypes(\"number\").columns if col != target_col]\n",
" for col in num_cols:\n",
" df[col] = df[col].astype(\"float\")\n",
" X = df[cat_cols + num_cols]\n",
" return X, y\n",
"\n",
"\n",
"def train_model(X, y):\n",
" cat_cols = list(X.select_dtypes(\"category\").columns)\n",
" X_trn, X_val, y_trn, y_val = train_test_split(X, y, test_size=0.2, random_state=1)\n",
" ds_trn = lgb.Dataset(X_trn, label=y_trn, categorical_feature=cat_cols, free_raw_data=False)\n",
" ds_val = lgb.Dataset(X_val, label=y_val, categorical_feature=cat_cols, free_raw_data=False)\n",
" model = lgb.train(\n",
" params={\"verbose\": -1, \"metric\": \"auc\", \"objective\": \"binary\"},\n",
" train_set=ds_trn,\n",
" valid_sets=[ds_val],\n",
" callbacks=[early_stopping(5)],\n",
" )\n",
" return model\n",
"\n",
"\n",
"import warnings\n",
"\n",
"warnings.filterwarnings(\"ignore\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "KRkpufuwougw",
"tags": []
},
"outputs": [],
"source": [
"# concatenate FAKE and REAL data together\n",
"df = pd.concat(\n",
" [\n",
" df_tgt.assign(split=\"REAL\"),\n",
" syn.assign(split=\"FAKE\"),\n",
" ],\n",
" axis=0,\n",
")\n",
"df.insert(0, \"split\", df.pop(\"split\"))\n",
"df.groupby(\"split\").size()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 184
},
"id": "i0rxFaBctmYD",
"outputId": "5f93c4c1-5042-4798-8160-1c691fa2bafc",
"tags": []
},
"outputs": [],
"source": [
"# take a 20% holdout dataset aside for evaluation\n",
"trn, hol = train_test_split(df, test_size=0.2, random_state=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 201
},
"id": "sStO_jULn8kL",
"outputId": "13475d7e-d388-4883-ea01-7b1592919223",
"tags": []
},
"outputs": [],
"source": [
"# train the discriminator on the remaining 80% training dataset\n",
"X_trn, y_trn = prepare_xy(trn, \"split\", \"FAKE\")\n",
"model = train_model(X_trn, y_trn)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 201
},
"id": "BKJ0R-HTr9bt",
"outputId": "a711e24e-3384-4586-ecab-964967693ea4",
"tags": []
},
"outputs": [],
"source": [
"# score the model on the holdout dataset, assigning a probability to each record on whether it's FAKE or REAL\n",
"X_hol, y_hol = prepare_xy(hol, \"split\", \"FAKE\")\n",
"hol.insert(1, \"is_fake\", model.predict(X_hol).round(4))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "tXiu9W3469Sc",
"tags": []
},
"outputs": [],
"source": [
"import seaborn as sns\n",
"import matplotlib.pyplot as plt\n",
"from sklearn.metrics import roc_auc_score, accuracy_score\n",
"\n",
"auc = roc_auc_score(y_hol, hol.is_fake)\n",
"acc = accuracy_score(y_hol, (hol.is_fake > 0.5).astype(int))\n",
"probs_df = pd.concat(\n",
" [\n",
" pd.Series(hol.is_fake, name=\"probability\").reset_index(drop=True),\n",
" pd.Series(y_hol, name=\"target\").reset_index(drop=True),\n",
" ],\n",
" axis=1,\n",
")\n",
"fig = sns.displot(data=probs_df, x=\"probability\", hue=\"target\", bins=20, multiple=\"stack\")\n",
"fig = plt.title(f\"Accuracy: {acc:.1%}, AUC: {auc:.1%}\")\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SZUfYStL7axE"
},
"source": [
"As you can see from above chart, the discriminator has learned to pick up some signals that allow it with a varying level of confidence to determine whether a record is FAKE or REAL. \n",
"\n",
"The AUC can be interpreted as the percentage of cases, where the discriminator is able to correctly spot the FAKE record, given a set of a FAKE and a REAL record."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Sample records, that seem very FAKE"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"hol.sort_values(\"is_fake\").tail(n=100).sample(n=5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In these cases, it is the mismatch between `education` and `education_num` that gives away the fact that these are FAKE. E.g., in the original data, education level `Assoc-acdm` was mapped to education number 12, whereas in the synthetic data we see various other numeric values."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"pd.crosstab(df_tgt.education, df_tgt.education_num)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"pd.crosstab(syn.education, syn.education_num)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Sample records, that seem very REAL\n",
"\n",
"I.e. these are type of records, that the synthesizer has apparently failed to create. Thus, as they are then absent from the synthetic data, the discriminator recognizes these as REAL."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"hol.sort_values(\"is_fake\").head(n=100).sample(n=5)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "eQMOiU1Bv6W4"
},
"source": [
"## Conclusion\n",
"\n",
"This tutorial has shown how to train a discriminator that is set out to distinguish between FAKE and REAL records. The better the quality of the generated synthetic data, the less likely the discriminator (as well as we humans) can tell them apart."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Further exercises\n",
"\n",
"In addition to walking through the above instructions, we suggest..\n",
"* measuring the Discriminator's AUC if more training samples are used\n",
"* using a different dataset, eg. the UCI bank-marketing dataset [[2](#refs)]\n",
"* using a different ML model for the discriminator, eg. a RandomForest model [[3](#refs)]\n",
"* using a different synthesizer, eg. SynthCity, SDV, etc."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "UW5ntiUB18yP"
},
"source": [
"## References\n",
"\n",
"1. https://archive.ics.uci.edu/ml/datasets/adult\n",
"1. https://archive.ics.uci.edu/ml/datasets/bank+marketing\n",
"1. https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html"
]
}
],
"metadata": {
"colab": {
"provenance": []
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "2.7.10"
},
"vscode": {
"interpreter": {
"hash": "767d51c1340bd893661ea55ea3124f6de3c7a262a8b4abca0554b478b1e2ff90"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}
\n",
"\n",
"In order to make the analysis more interesting, we intentionally create synthetic data of lower quality, by limiting the training samples to only a thousand records. Otherwise, the discriminator would not be able to find much signal, if the synthesizer, like MOSTLY AI Synthetic Data SDK, is of very high quality."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MKRa93uuSqZS"
},
"source": [
"## Synthesize Data via MOSTLY AI\n",
"\n",
"For this tutorial, we will be using again the UCI Adult Income [[1](#refs)] dataset, which consists of 48,842 records across 15 attributes.\n",
"\n",
"We will use the Synthetic Data SDK to create a Generator and then use that Generator to create a Synthetic dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%pip install -U mostlyai # or: pip install -U 'mostlyai[local]'\n",
"%pip install scikit-learn seaborn lightgbm"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"\n",
"# fetch original data\n",
"df_tgt = pd.read_csv(\"https://github.com/mostly-ai/public-demo-data/raw/dev/census/census.csv.gz\")\n",
"df_tgt"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from mostlyai.sdk import MostlyAI\n",
"\n",
"# initialize SDK\n",
"mostly = MostlyAI()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# create generator with a sample of 5,000\n",
"g = mostly.train(\n",
" config={\n",
" \"name\": \"Fake vs. Real Tutorial - Census Data\",\n",
" \"tables\": [\n",
" {\n",
" \"name\": \"data\",\n",
" \"data\": df_tgt,\n",
" \"tabular_model_configuration\": {\n",
" \"max_sample_size\": 5_000,\n",
" \"max_training_time\": 2,\n",
" },\n",
" }\n",
" ],\n",
" }\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Generate synthetic data\n",
"syn = mostly.probe(g, size=5_000)\n",
"print(f\"Created synthetic data with {syn.shape[0]:,} records and {syn.shape[1]:,} attributes\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "OgvJ0XoWTHoX"
},
"source": [
"## Train Discriminator"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Rl6-YXB_e0Ac",
"tags": []
},
"outputs": [],
"source": [
"import lightgbm as lgb\n",
"from lightgbm import early_stopping\n",
"from sklearn.model_selection import train_test_split\n",
"\n",
"\n",
"def prepare_xy(df, target_col, target_val):\n",
" # split target variable `y`\n",
" y = (df[target_col] == target_val).astype(int)\n",
" # convert strings to categoricals, and all others to floats\n",
" str_cols = [col for col in df.select_dtypes([\"object\", \"string\"]).columns if col != target_col]\n",
" for col in str_cols:\n",
" df[col] = pd.Categorical(df[col])\n",
" cat_cols = [col for col in df.select_dtypes(\"category\").columns if col != target_col]\n",
" num_cols = [col for col in df.select_dtypes(\"number\").columns if col != target_col]\n",
" for col in num_cols:\n",
" df[col] = df[col].astype(\"float\")\n",
" X = df[cat_cols + num_cols]\n",
" return X, y\n",
"\n",
"\n",
"def train_model(X, y):\n",
" cat_cols = list(X.select_dtypes(\"category\").columns)\n",
" X_trn, X_val, y_trn, y_val = train_test_split(X, y, test_size=0.2, random_state=1)\n",
" ds_trn = lgb.Dataset(X_trn, label=y_trn, categorical_feature=cat_cols, free_raw_data=False)\n",
" ds_val = lgb.Dataset(X_val, label=y_val, categorical_feature=cat_cols, free_raw_data=False)\n",
" model = lgb.train(\n",
" params={\"verbose\": -1, \"metric\": \"auc\", \"objective\": \"binary\"},\n",
" train_set=ds_trn,\n",
" valid_sets=[ds_val],\n",
" callbacks=[early_stopping(5)],\n",
" )\n",
" return model\n",
"\n",
"\n",
"import warnings\n",
"\n",
"warnings.filterwarnings(\"ignore\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "KRkpufuwougw",
"tags": []
},
"outputs": [],
"source": [
"# concatenate FAKE and REAL data together\n",
"df = pd.concat(\n",
" [\n",
" df_tgt.assign(split=\"REAL\"),\n",
" syn.assign(split=\"FAKE\"),\n",
" ],\n",
" axis=0,\n",
")\n",
"df.insert(0, \"split\", df.pop(\"split\"))\n",
"df.groupby(\"split\").size()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 184
},
"id": "i0rxFaBctmYD",
"outputId": "5f93c4c1-5042-4798-8160-1c691fa2bafc",
"tags": []
},
"outputs": [],
"source": [
"# take a 20% holdout dataset aside for evaluation\n",
"trn, hol = train_test_split(df, test_size=0.2, random_state=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 201
},
"id": "sStO_jULn8kL",
"outputId": "13475d7e-d388-4883-ea01-7b1592919223",
"tags": []
},
"outputs": [],
"source": [
"# train the discriminator on the remaining 80% training dataset\n",
"X_trn, y_trn = prepare_xy(trn, \"split\", \"FAKE\")\n",
"model = train_model(X_trn, y_trn)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 201
},
"id": "BKJ0R-HTr9bt",
"outputId": "a711e24e-3384-4586-ecab-964967693ea4",
"tags": []
},
"outputs": [],
"source": [
"# score the model on the holdout dataset, assigning a probability to each record on whether it's FAKE or REAL\n",
"X_hol, y_hol = prepare_xy(hol, \"split\", \"FAKE\")\n",
"hol.insert(1, \"is_fake\", model.predict(X_hol).round(4))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "tXiu9W3469Sc",
"tags": []
},
"outputs": [],
"source": [
"import seaborn as sns\n",
"import matplotlib.pyplot as plt\n",
"from sklearn.metrics import roc_auc_score, accuracy_score\n",
"\n",
"auc = roc_auc_score(y_hol, hol.is_fake)\n",
"acc = accuracy_score(y_hol, (hol.is_fake > 0.5).astype(int))\n",
"probs_df = pd.concat(\n",
" [\n",
" pd.Series(hol.is_fake, name=\"probability\").reset_index(drop=True),\n",
" pd.Series(y_hol, name=\"target\").reset_index(drop=True),\n",
" ],\n",
" axis=1,\n",
")\n",
"fig = sns.displot(data=probs_df, x=\"probability\", hue=\"target\", bins=20, multiple=\"stack\")\n",
"fig = plt.title(f\"Accuracy: {acc:.1%}, AUC: {auc:.1%}\")\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SZUfYStL7axE"
},
"source": [
"As you can see from above chart, the discriminator has learned to pick up some signals that allow it with a varying level of confidence to determine whether a record is FAKE or REAL. \n",
"\n",
"The AUC can be interpreted as the percentage of cases, where the discriminator is able to correctly spot the FAKE record, given a set of a FAKE and a REAL record."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Sample records, that seem very FAKE"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"hol.sort_values(\"is_fake\").tail(n=100).sample(n=5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In these cases, it is the mismatch between `education` and `education_num` that gives away the fact that these are FAKE. E.g., in the original data, education level `Assoc-acdm` was mapped to education number 12, whereas in the synthetic data we see various other numeric values."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"pd.crosstab(df_tgt.education, df_tgt.education_num)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"pd.crosstab(syn.education, syn.education_num)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Sample records, that seem very REAL\n",
"\n",
"I.e. these are type of records, that the synthesizer has apparently failed to create. Thus, as they are then absent from the synthetic data, the discriminator recognizes these as REAL."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"hol.sort_values(\"is_fake\").head(n=100).sample(n=5)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "eQMOiU1Bv6W4"
},
"source": [
"## Conclusion\n",
"\n",
"This tutorial has shown how to train a discriminator that is set out to distinguish between FAKE and REAL records. The better the quality of the generated synthetic data, the less likely the discriminator (as well as we humans) can tell them apart."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Further exercises\n",
"\n",
"In addition to walking through the above instructions, we suggest..\n",
"* measuring the Discriminator's AUC if more training samples are used\n",
"* using a different dataset, eg. the UCI bank-marketing dataset [[2](#refs)]\n",
"* using a different ML model for the discriminator, eg. a RandomForest model [[3](#refs)]\n",
"* using a different synthesizer, eg. SynthCity, SDV, etc."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "UW5ntiUB18yP"
},
"source": [
"## References\n",
"\n",
"1. https://archive.ics.uci.edu/ml/datasets/adult\n",
"1. https://archive.ics.uci.edu/ml/datasets/bank+marketing\n",
"1. https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html"
]
}
],
"metadata": {
"colab": {
"provenance": []
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "2.7.10"
},
"vscode": {
"interpreter": {
"hash": "767d51c1340bd893661ea55ea3124f6de3c7a262a8b4abca0554b478b1e2ff90"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}